Lecture
Agents based on purpose
Knowledge of the current state of the environment is not always enough to make a decision about what to do. For example, at the crossroads of a taxi can turn left, turn right or go straight. The right decision depends on where the taxi should go. In other words, the agent requires not only a description of the current state, but also a kind of information about the target, which describes the desired situations, such as transporting the passenger to the destination. An agent program can combine this information with information about the results of possible actions (with the same information as the one used to update the internal state of the reflex agent) to select actions that would achieve this goal.
The structure of the agent acting on the basis of the goal is shown in the figure. Sometimes the task of choosing an action based on a goal is solved simply when the achievement of a goal immediately becomes the result of a single action, and sometimes this task becomes more complex and the agent needs to consider long sequences of movements and turns to find a way to achieve the goal. The subareas of artificial intelligence devoted to the development of sequences of actions that allow an agent to achieve his goals are search and planning.
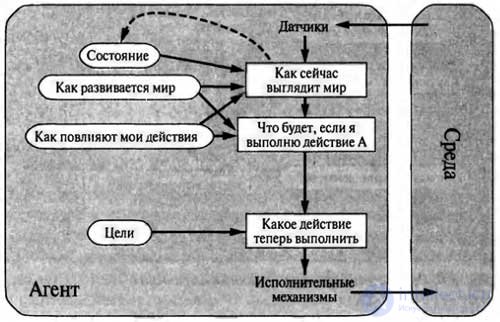
It should be borne in mind that this kind of decision-making procedure is fundamentally different from the condition-action rule application procedure described above, because it has to reflect on the future, answering two questions: “What happens if I do this and that?” "And" Will this allow me to achieve satisfaction? "In reflex agent projects, such information is not explicitly presented, since the built-in rules establish a direct correspondence between perceptions and actions. The reflex agent slows down when he sees the deceleration signals of the car in front of the vehicle, and the agent based on the target can judge that if the brake lights on the car in front lit up, it slows down.
Considering the principle on which this world usually changes, for it the only action allowing to achieve such a goal as preventing collisions with other cars is braking. Although at first glance it seems that the agent based on the goal is less effective, it is more flexible, since the knowledge on which its decisions are based is presented explicitly and can be modified. If it starts to rain, the agent can update his knowledge of how effectively his brakes will work now; this automatically causes a change in all relevant rules of behavior to reflect the new conditions. For a reflex agent, on the other hand, in such a case, a whole series of conditions — action — would have to be rewritten.
The behavior of the agent based on the target can be easily changed to direct it to another location, and the reflex agent rules that indicate where to turn and where to go straight will only be applicable for a single destination; in order for this agent to be sent to another place, all these rules must be replaced.
Utility based agents
In fact, in most of the variants of the environment, it is not enough just to take targets into account to develop high-quality behavior. For example, there are usually many sequences of actions that allow taxis to reach their destination (and thereby achieve the goal), but some of these sequences provide a faster, safer, more reliable or less expensive ride than others. Goals allow only a hard binary distinction between states of “satisfaction” and “dissatisfaction”, while more general performance indicators should provide a comparison of different states of the world in exact accordance with how satisfied an agent becomes if they are achieved.
Since the concept of “satisfaction” does not seem to be entirely scientific, the terminology is often used, according to which the state of the world, more preferable than the other, is considered to have a higher utility for the agent.
The utility function maps a state (or a sequence of states) to a real number, which indicates the corresponding degree of agent satisfaction. A complete specification of the utility function provides the ability to make rational decisions in the two cases described below, when goals do not allow this. First, if there are conflicting objectives, such that only some of them can be achieved (for example, or speed, or safety), then the utility function allows you to find an acceptable compromise. Secondly, if there are several goals to which an agent can strive, but none of them can be achieved with all certainty, then the utility function provides a convenient way of weighted assessment of the probability of success, taking into account the importance of goals.
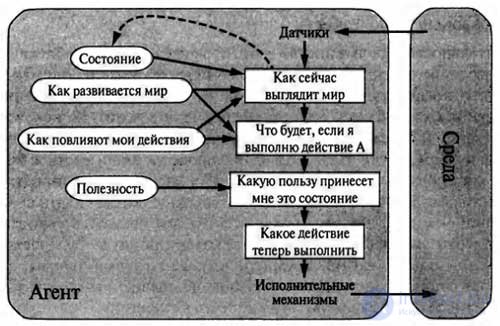
Any rational agent should behave as if he possessed a utility function, the expected value of which he is trying to maximize. Therefore, an agent with an explicitly specified utility function has the ability to make rational decisions and is able to do this with the help of a general-purpose algorithm that does not depend on the specific utility function being maximized. Due to this, the “global” definition of rationality (according to which agent functions with the highest performance are considered rational) is converted into a “local” restriction on the projects of rational agents, which can be expressed as a simple program.
Learning agents
Above, agent programs have been described that use various methods of selecting actions. But so far no information has been given on how agent programs are created. In his famous early article, Turing analyzed the idea of how manual programming of the intelligent machines he proposed should actually be carried out. He estimated the amount of work that would be required for this, and came to this conclusion: “It would be desirable to have some more productive method.”
The method he proposed was that it was necessary to create learning machines and then conduct their training. Now this method has become the dominant method of creating the most modern systems in many areas of artificial intelligence.
As noted above, the training has another advantage: it allows the agent to function in initially unknown variants of the environment and become more competent than what his initial knowledge could allow.
As shown in the figure, the structure of the learning agent can be divided into four conceptual components. The most important difference is between the training component, which is responsible for making improvements, and the productive component, which provides a choice of external actions.
The training component uses the feedback information from the critic to evaluate how the agent acts, and determines how the productive component should be modified in order for it to operate more successfully in the future.
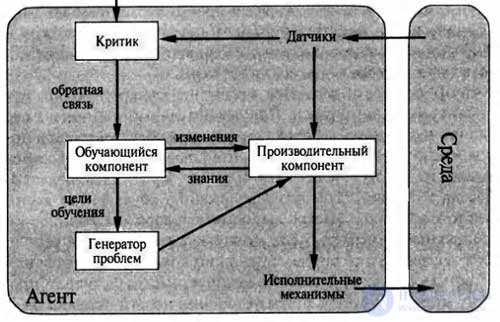
The project of the training component largely depends on the project of the production component. When attempting to design an agent who learns certain abilities, one must first of all seek to find the answer to the question: “What kind of productive component will my agent need after he has been trained in how to perform his functions?” Rather than on the question: “How to begin the task of learning how to perform these functions? ”
After the agent itself is designed, you can begin to design training mechanisms to improve any part of this agent. The critic informs the training component how well the agent works with regard to the constant standard of performance. The critic is necessary because the perception results themselves do not give any indication as to whether the agent works successfully.
For example, a chess program can get perception results indicating that it mated its opponent, but it needs a performance standard that would allow it to be determined that it is a good result; perception data itself does not say anything about it. It is important that the performance standard is constant. In principle, this standard should be considered as completely external to the agent, since the agent should not be able to modify it so that it more closely matches its own behavior.
The final component of the learning agent is the problem generator. His task is to propose actions that should lead to a new and informative experience. The fact is that if the productive component is left to itself, it continues to perform the actions that are best from the point of view of what it knows. But if an agent is ready to experiment a bit and in the short term to perform actions that may not be entirely optimal, he can find much better actions from a long-term perspective.
The problem generator is designed precisely to propose such research activities. That is what scientists are doing, conducting experiments. Galileo did not believe that dropping stones from the top of the Tower of Pisa was an end in itself. He did not simply try to smash the rubble or to physically influence the heads of unlucky passersby. His plan was to change the views that had developed in his own head, formulating the best theory of the movement of objects.
In order to transfer this entire project to a specific ground, let us return to the example of an automated taxi. The productive component consists of the collection of knowledge and procedures that a taxi driver applies when choosing his driving actions. A taxi driver with the help of this productive component leaves the road and drives his car. The critic observes the world and in the course of this passes the relevant information to the learning component.
For example, after a taxi quickly makes a turn to the left, crossing three lanes, the critic notices which shocking expressions other drivers use. Based on this experience, the training component is able to formulate a rule that states that this is an unacceptable action, and the productive component is modified by setting a new rule.
The problem generator can identify some areas of behavior that need improvement, and suggest experiments, such as checking brakes on different pavements and under different conditions.
The learning component can make changes to any of the “knowledge” components. In the simplest cases, training will be carried out directly on the basis of the sequence of acts of perception. Observing the pairs of successive states of the environment allows the agent to master information about “how the world changes”, and observing the results of my actions can give the agent the opportunity to learn “what influence my actions have”.
For example, after a taxi driver applies a certain amount of brake pressure while driving on a wet road, he soon learns what speed reduction has actually been achieved. Obviously, these two learning tasks become more complex if the environment is only partially observable.
Those forms of training that were described in the previous paragraph do not require access to an external performance standard, or rather, they use a universal standard, according to which the predictions made must be consistent with the experiment. The situation becomes a bit more complicated when it comes to a utility-based agent who seeks to master utility information in the learning process.
For example, suppose an agent driving a taxi stops receiving tips from passengers who feel completely overwhelmed during the tedious trip. An external performance standard should inform the agent that the lack of a tip is a negative contribution to its overall performance; in this case, the agent gets the opportunity to learn as a result of training that the rough maneuvers that weary passengers, do not allow to increase the assessment of its own utility function.
In this sense, the performance standard allows you to select a certain part of the input perception results as a reward (or penalty) directly provided by feedback data that affect the quality of the agent's behavior.
It is from this point of view that rigidly fixed performance standards, such as pain or hunger, which characterize animal life, can be considered.
Summing up, we note that agents have a wide variety of components, and these components themselves can be represented in the agent's program in many ways, so it seems that the variety of teaching methods is extremely large. Nevertheless, all these methods have a single unifying aspect.
The learning process carried out in intelligent agents can generally be described as the process of modifying each agent component to ensure that these components more accurately match the available feedback information and thereby improve the overall performance of the agent.

Comments
To leave a comment
Intelligent Agents. Multi agent systems
Terms: Intelligent Agents. Multi agent systems